- Autonomous Systems @ UK AI Safety Institute (AISI)
- DPhil AI Safety @ Oxford (Hertford college, CS dept, AIMS CDT)
- Former senior data scientist and software engineer + SERI MATS
I'm particularly interested in sustainable collaboration and the long-term future of value. I'd love to contribute to a safer and more prosperous future with AI! Always interested in discussions about axiology, x-risks, s-risks.
I enjoy meeting new perspectives and growing my understanding of the world and the people in it. I also love to read - let me know your suggestions! In no particular order, here are some I've enjoyed recently
- Ord - The Precipice
- Pearl - The Book of Why
- Bostrom - Superintelligence
- McCall Smith - The No. 1 Ladies' Detective Agency (and series)
- Melville - Moby-Dick
- Abelson & Sussman - Structure and Interpretation of Computer Programs
- Stross - Accelerando
- Graeme - The Rosie Project (and trilogy)
Cooperative gaming is a relatively recent but fruitful interest for me. Here are some of my favourites
- Hanabi (can't recommend enough; try it out!)
- Pandemic (ironic at time of writing...)
- Dungeons and Dragons (I DM a bit and it keeps me on my creative toes)
- Overcooked (my partner and I enjoy the foody themes and frantic realtime coordination playing this)
People who've got to know me only recently are sometimes surprised to learn that I'm a pretty handy trumpeter and hornist.
Posts
Wiki Contributions
Comments
I guess my question would be 'how else did you think a well-generalising sequence model would achieve this?' Like, what is a sufficient world model but a posterior over HMM states in this case? This is what GR theorem asks. (Of course, a poorly-fit model might track extraneous detail or have a bad posterior.)
From your preamble and your experiment design, it looks like you correctly anticipated the result, so this should not have been a surprise (to you). In general I object to being sold something as surprising which isn't (it strikes me as a lesser-noticed and perhaps oft-inadvertent rhetorical dark art and I see it on the rise on LW, which is sad).
That said, since I'm the only one objecting here, you appear to be more right about the surprisingness of this!
The linear probe is new news (but not surprising?) on top of GR, I agree. But the OP presents the other aspects as the surprises, and not this.
Nice explanation of MSP and good visuals.
This is surprising!
Were you in fact surprised? If so, why? (This is a straightforward consequence of the good regulator theorem[1].)
In general I'd encourage you to carefully track claims about transformers, HMM-predictors, and LLMs, and to distinguish between trained NNs and the training process. In this writeup, all of these are quite blended.
Incidentally I noticed Yudkowsky uses 'brainware' in a few places (e.g. in conversation with Paul Christiano). But it looks like that's referring to something more analogous to 'architecture and learning algorithms', which I'd put more in the 'software' camp when in comes to the taxonomy I'm pointing at (the 'outer designer' is writing it deliberately).
Unironically, I think it's worth anyone interested skimming that Verma & Pearl paper for the pictures :) especially fig 2
Mmm, I misinterpreted at first. It's only a v-structure if and are not connected. So this is a property which needs to be maintained effectively 'at the boundary' of the fully-connected cluster which we're rewriting. I think that tallies with everything else, right?
ETA: both of our good proofs respect this rule; the first Reorder in my bad proof indeed violates it. I think this criterion is basically the generalised and corrected version of the fully-connected bookkeeping rule described in this post. I imagine if I/someone worked through it, this would clarify whether my handwave proof of Frankenstein Stitch is right or not.
That's concerning. It would appear to make both our proofs invalid.
But I think your earlier statement about incoming vs outgoing arrows makes sense. Maybe Verma & Pearl were asking for some other kind of equivalence? Grr, back to the semantics I suppose.
Aha. Preserving v-structures (colliders like ) is necessary and sufficient for equivalence[1]. So when rearranging fully-connected subgraphs, certainly we can't do it (cost-free) if it introduces or removes any v-structures.
Plausibly if we're willing to weaken by adding in additional arrows, there might be other sound ways to reorder fully-connected subgraphs - but they'd be non-invertible. Haven't thought about that.
Verma & Pearl, Equivalence and Synthesis of Causal Models 1990 ↩︎
Mhm, OK I think I see. But appear to me to make a complete subgraph, and all I did was redirect the . I confess I am mildly confused by the 'reorder complete subgraph' bookkeeping rule. It should apply to the in , right? But then I'd be able to deduce which is strictly different. So it must mean something other than what I'm taking it to mean.
Maybe need to go back and stare at the semantics for a bit. (But this syntactic view with motifs and transformations is much nicer!)
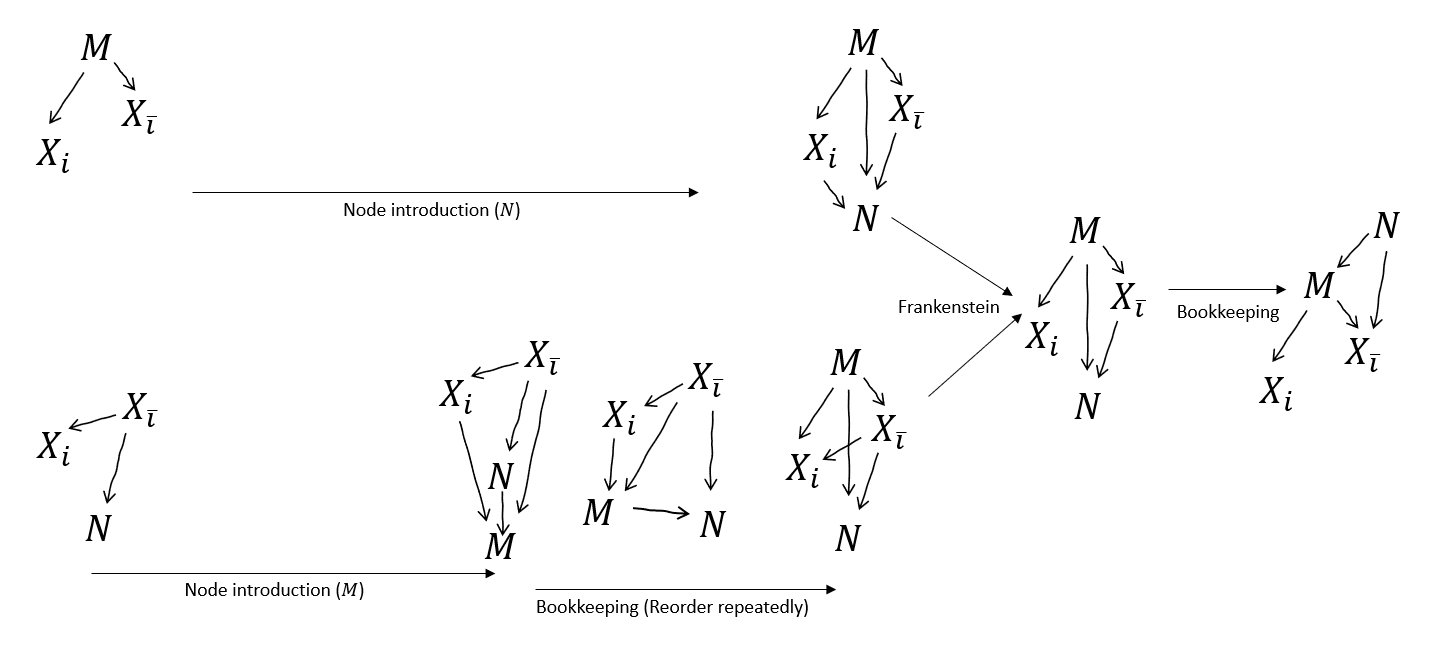
Perhaps more importantly, I think with Node Introduction we really don't need after all?
With Node Introduction and some bookkeeping, we can get the and graphs topologically compatible, and Frankenstein them. We can't get as neat a merge as if we also had - in particular, we can't get rid of the arrow . But that's fine, we were about to draw that arrow in anyway for the next step!
Is something invalid here? Flagging confusion. This is a slightly more substantial claim than the original proof makes, since it assumes strictly less. Downstream, I think it makes the Resample unnecessary.
ETA: it's cleared up below - there's an invalid Reorder here (it removes a v-structure).
Lol! I guess if there was a more precise theorem statement in the vicinity gestured, it wasn't nonsense? But in any case, I agree the original presentation is dreadful. John's is much better.
A quick go at it, might have typos.
Suppose we have
and a predictor
with structure
X→YX→RY→S→^Y→R
Then GR trivially says S (predictor state) should model the posterior P(X|Y).
Now if these are all instead processes (time-indexed), we have HMM
and predictor process
with structure
Xt→Xt+1Xt→YtSt−1→StYt→St→^Yt+1→Rt+1Yt+1→Rt+1
Drawing together (Xt+1,Yt+1,^Yt+1,Rt+1) as Gt the 'goal', we have a GR motif
Xt→YtYt→St→GtSt−1→StXt→Gt
so St must model P(Xt|St−1,Yt); by induction that is P(Xt|S0,Y1,...,Yt).